Why user-level LTV models are essential for post-iOS 14 user acquisition
It has only been a few weeks since Apple’s iOS14 announcement, but the performance marketing ecosystem is already adapting to its new privacy features. Deterministic campaign attribution, a cornerstone technology in running and evaluating performance campaigns, will be replaced with Apple’s SKAdnetwork. Granular, persistent, cross-device performance analysis will be made more challenging by a series of limitations designed to obfuscate user identity.
AlgoLift is developing what we believe is a robust and mathematically sound approach to accurately attribute predicted revenue across campaigns using probabilistic attribution. Underpinning this approach are 5 key hypotheses:
- Attribution will become a data science initiative requiring a mathematical framework. 1:1 attribution (fingerprinting ID) between a user and campaign goes against the spirit of iOS14 and doesn’t properly capture uncertainty in user origination.
- Outputting deterministic attribution from campaign to install using probabilistic inputs is error-prone and sub-optimal.
- Probabilistic campaign membership is useful to an automated system, but inefficient for a human operator.
- A user-level LTV model is essential for leveraging the outputs of a probabilistic attribution framework.
In a previous article, we discussed the first 3 hypotheses in depth. In this piece, we’d like to take the opportunity to share in more detail why a cohort LTV model significantly inhibits the ability to accurately attribute revenue to the correct campaign, and describe why a user-level LTV model provides more powerful capabilities.
Cohort LTV model
Cohort LTV models are easier to implement than user-level and are therefore widely adopted. For the purposes of user acquisition, one might need to use a cohort model because:
- Data is only available at a cohort level
- Predictions are only needed at the cohort level
- User-level LTV is too hard to implement due to the data science capabilities needed
- A secondary validation for user-level LTV is needed
A cohort LTV model groups installs based on similar advertising campaign attributes (geo, ad network, platform) and their respective downstream revenue and in-app engagements to build a model that predicts the future performance of those installs as a cohort. For example, you might build a cohort model to predict the future predicted revenue from Facebook, US, iOS users. In the current paradigm, the installs from campaigns targeted to this audience would all be grouped together and assigned the same predicted LTV based on observed downstream revenue events. This model can provide a sufficient level of accuracy for user acquisition purposes and many of the largest app developers use this type of model today.
As users upgrade to iOS14 access to downstream revenue and in-app engagement events will be significantly degraded, removing the ability to split cohort models by channel or campaign granularity.
The crippling restriction of a cohort model is that it’s impossible to break down a cohort LTV prediction to understand the distribution of revenue or in-app engagements within a cohort. As a result, there is no way to accurately probabilistically attribute a share of the cohort’s revenue to a campaign.
User-level LTV model
A user-level LTV offers significant flexibility over and above the revenue prediction benefit offered by a cohort model. A user-level model allows the operator to:
- Dissect a user base by any dimension and examine LTV across any slice of installs (eg: geo, campaign, ad network, sub-publisher, tutorial finishers, users who’ve taken a free trial)
- Power user acquisition automation by understanding the distribution of revenue within a campaign and applying the correct treatment for small cohorts (eg sub-publishers)
- Integrate with CRM tools; along with LTV predictions, churn and conversion probabilities, user-level forecasts can be cohorted and used to target in-app messages, push notifications and email to the right audience
Added to the reasons above and in the iOS14 paradigm, a user-level model also provides a:
- Flexible model that can leverage probabilistic attribution on iOS14
In short, user-level forecasting can be easily rolled up to the cohort level, but not the other way around. Prior to iOS14, the complexity of user-level modeling may not have seemed worth the effort to some advertisers. After iOS14 is released, a user-level LTV model will be essential for correctly attributing revenue to campaigns.
Probabilistic attribution: Cohort vs. User-level LTV model
We can show the stark differences in the outcome of the two types of model applied to probabilistic attribution when we give a simple example. Table 1 shows 5 hypothetical users that can belong to one of three campaigns or organic (more details on why in our previous article). SKAdnetwork obfuscates user-level campaign and ad network attribution data, so geo and device parameters are the only categorical differentiators between users. In this simple case, geo can be US or CA. The cohort model is, by definition, limited to the granularity allowed by the available categorical variables. All US and CA users, respectively, get the same pRevenue (predicted revenue).
The user-level LTV model utilizes individual behavioral data to calculate pRevenue. Furthermore, it uses a combination of network-side, user behavioral, and device-level information to assign user-level campaign membership probability for each app user.
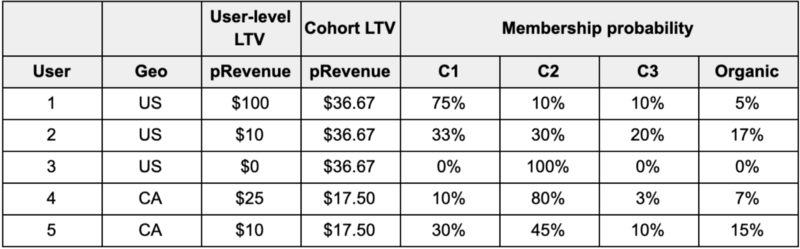
Table 1: Hypothetical user-level LTV projections and cohort LTV projections and membership probabilities for 5 users with 3 campaigns. User 3 was an opt-in iOS user with fully known attribution to campaign C2.
Table 2 shows the ad network side information for these hypothetical campaigns. C1 is a campaign on ad network N1 whereas C2 and C3 run on ad network N2. The geo distribution and spend are also reported for each campaign. User-level pRevenue was calculated by summing user-level revenue weighted by membership probability. Cohort level pRevenue was calculated by summing the cohort-level geo pRevenue from Table 1 by campaign geo composition. pROAS (predicted return on ad spend) was the ratio of pRevenue to spend in both cases.
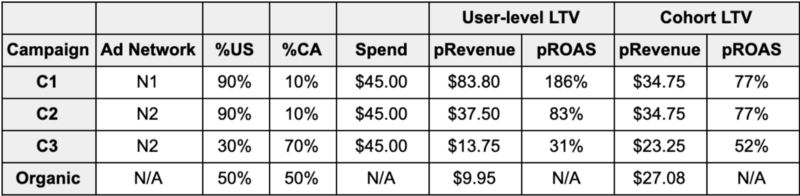
Table 2: Campaign revenue and ROAS for the user-level LTV model and cohort model
The cohort model gives Campaigns C1 and C2 the same expected pROAS of 77% — this is because they have the same geo-distribution. The user-level model gives a pROAS of C1=186% and C2=83% — a significant difference from the cohort model. Using the cohort model would result in a significant allocation of budget to the wrong campaign.
Most advertisers currently have cohort models with an ad network as the input. The incoming change will remove the possibility of using ad network as a meaningful attribute for cohort differential and leaving the model ineffective in a post-iOS14 world.
In this article, we’ve outlined one example of how iOS14 disrupts the effectiveness of a cohort model, but this can be extrapolated across other categorical variables that render the cohort model useless when predicting campaign LTV.We then turn to user-level LTV forecasting and probabilistic campaign attribution for accurate probabilistic pROAS estimation.